背景简介
代谢全谱为非靶向代谢组学分析,采用色谱-质谱联用技术采集样品的代谢谱图,比较不同组样品代谢产物的含量,鉴定差异表达的代谢物,并探索差异代谢物之间的代谢通路。代谢组学分析技术已广泛应用于疾病诊断、药物靶点发现、疾病机理研究、营养食品科学、毒理学、植物学等相关领域,已成为目前研究的新热点。
技术优势
高灵敏度:基于先进的液相串联质谱技术,可检测到pg级化合物。
高覆盖度:检测多达上千种化合物,胜任热不稳定、不易挥发、不易衍生化等物质的检测。
低成本:侧重于相关特定组分共性研究,筛检有意义代谢产物,检测成本较低。
跨组学分析:提供从基因组学、转录组学、蛋白质组学、到代谢组学的全程科技服务,深度剖析生物学现象。
技术路线

分析内容

样本类型
细胞,组织,尿液,全血,血清,血浆等
建议起始量(单次):血浆或血清>300 μL,尿液> 5 mL,组织> 100 mg,细胞>107个。
Q1: 代谢物鉴定搜索的数据库有哪些?
A :搜索的数据库都是公共库,KEGG、METLIN等等,精确度都在10ppm以内(一个分子量仍然会对应多个代谢物),如果库里面有相应的二级谱图,那么鉴定就可以更加的精确,后续如果要验证的话,可购买标准品。
Q2:代谢全谱对于样本数量有要求吗?
A:对于目标在于寻找差异代谢物的代谢全谱来说,临床样本数量每组建议不低于30个。模式生物及动植物样本,建议不少于10个。
Q3:代谢组学全谱分析和脂质代谢组学分析有什么区别?
A:代谢组学全谱分析是对生物体内所有代谢物进行定量分析,并寻找代谢物与生理病理变化相对关系的研究方式,其研究对象是相对分子质量小于1000Da的小分子物质,如脂类、酮类、有机酸等。众所周知,基因组学和蛋白质组学分别从基因和蛋白质层面探寻生命活动,但实际上细胞内许多生命活动是发生在代谢物层面的,如细胞信号释放、能量传递和细胞间通信等都受代谢物调控。代谢组学全谱分析是通过单变量及多变量分析发现差异表达的代谢物信息,从而反映细胞所处的环境以及其与外界影响因素之间的相互作用关系。
脂质组学(lipidomics)是研究生物体的脂类组成,脂类代谢以及脂类相互作用的一门学科,是代谢组学最重要的分支。脂质具有多种重要的生物学功能,如物质运输、能量代谢、信息传递及代谢调控等,脂质代谢异常可引发诸多人类疾病,包括阿兹海默症、糖尿病、肥胖症、动脉粥样硬化等。
案例一:高粱家系初生和次生代谢物的非靶向代谢组学研究
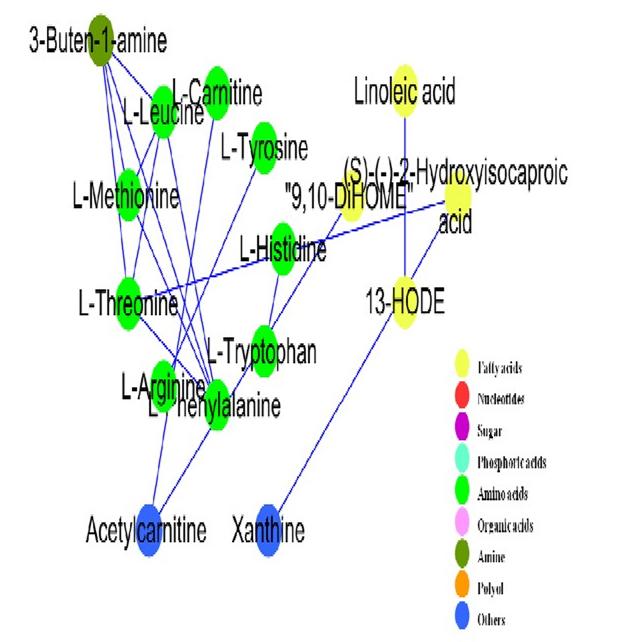
本研究以高粱为研究对象,利用非靶向代谢组学技术分析代谢物与形态生理变化间的关系。选择11个高粱二倍体家系叶组织进行非靶向代谢组学分析,结果显示1181种代谢物中有956个代谢物差异表达(p < 0.05)。单变量和多变量分析显示,大多数代谢物因高粱家系和品种的不同而不同。其中有384种代谢物至少与一个形态生理特性相关,如糖化类黄酮和绿原酸等次生代谢物。代谢组学分析揭示了两个或两个以上的形态生理特性之间的关系,结果表明绿原酸和莽草酸与高粱光合作用、苗期生长和最终产量有关。
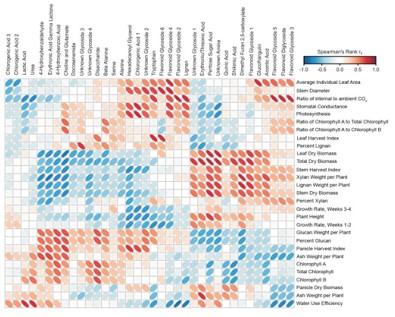
图 代谢产物与形态生理特征的关系
案例二:慢性髓细胞白血病患者血浆和白细胞的代谢谱分析
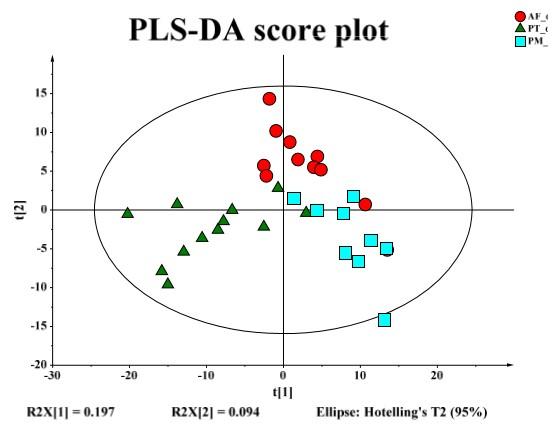
酪氨酸激酶抑制剂(TKIs)的发现为慢性髓细胞白血病(CML)患者的治疗带来重大突破。CML的发病原因与Bcr-Abl蛋白和酪氨酸激酶活性密切相关。TKIs通过抑制ATP结合,因而避免信号通路恶变。然而,有关TKI治疗对CML患者代谢物的影响尚未知。本研究选定正常人群,新诊断患者,分别使用TKI(伊马替尼、尼罗替尼、达沙替尼)治疗的患者,羟基脲治疗的患者,利用代谢组学技术对这6种人群的血浆和白细胞样本进行分析。白细胞主成分分析结果显示,新诊断患者/经羟基脲治疗患者的代谢物,与TKIs治疗患者/健康人群的代谢物存在显著分离,主要表现在糖酵解、三羧酸循环和氨基酸代谢的差异上。代谢组谱分析可以作为CML患者TKIs治疗响应的早期评估工具。
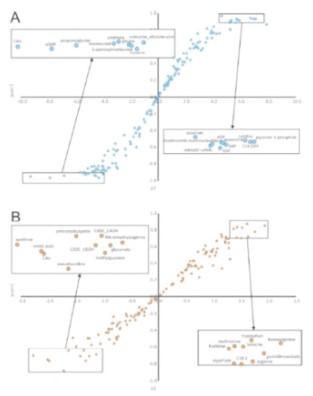
图 对照组与新诊断患者的白细胞和血浆S-plots图
参考文献
1.Turner M F, Heuberger A L, Kirkwood J S, et al. Non-targeted Metabolomics in Diverse Sorghum Breeding Lines Indicates Primary and Secondary Metabolite Profiles Are Associated with Plant Biomass Accumulation and Photosynthesis[J]. Frontiers in Plant Science, 2016, 7(59).
2.Karlíková R, Široká J, Friedecký D, et al. Metabolite profiling of the plasma and leukocytes of chronic myeloid leukemia patients[J]. Journal of Proteome Research, 2016, 15(9).
多元统计分析(PCA分析)主成分分析将代谢物变量按一定的权重通过线性组合后产生新的特征变量,通过主要新 变量(主成分)对各组数据进行归类,去除重复性差的样本(离群样本)和异常样本 。因无外加人为因素,得到的 PCA 模型 反映了代谢组数据的原始状态,有利于掌握此数据的整体情况并对数据从整体上进行把握,尤其是有利于发现和剔除异常样品,并提高模型的准确性。通过 PCA分析所得 到的图谱即称为 PCA 得分图(score scatter plot),每个样本在图上的位置由不同变 量的加权得分所决定。由 PCA 得分图可以观察样本的聚集、离散程度:样本分布点越靠近,说明这些样本中所含有的变量/分子的组成和浓度越接近;反之,样本点越远离, 其差异越大。

多元统计分析(PLSDA分析)与 PCA 只有一个数据集不同,PLS-DA 在分析时必须对样品进行指定并分组, 这样模型会自动加上另外一个隐含的数据集 Y,该数据集变量数等于组别数。 PLS-DA 是目前代谢组学数据分析中最常使用的一种分类方法,它在降维的同 时结合了回归模型,并利用一定的判别阈值对回归结果进行判别分析。
差异代谢物层次聚类分析聚类分析被用于判断代谢物在不同实验条件下的代谢模式。代谢模式相似的代谢物具有相似的功能,或是共同参与同一代谢过程或者细胞通路。因此通过将代谢模式相同或者相近的代谢物聚成类,可以用来推测未知代谢物或者已知代谢物的功能。以不 同实验条件下的代谢物的相对值为代谢水平,做层次聚类分析,不同颜色的区域代表不同的聚类分组信息,同组内的代谢表达模式相近,可能具有相似的功能或参与相同的生物学过程。

代谢物关联网络分析代谢物关联网络分析是根据代谢物信号值的动态变化,计算代谢物之间的共表达关系,来建立代谢相关调控模型,得到代谢物间调控关系及调控方向,从而寻找一个或多个物种在不同 发育阶段,或者不同组织在不同条件或处理下的全部代谢物调控网络模型以及关键代谢物,从而系统的研究生物体复杂的生命现象。通常梯度样本进行关联网络分析才具有意义,例如时间序列样本、不同发育阶段、梯度浓度处理样本等。